Eval feedback loops
In AI engineering, it can be tough to understand how a change will impact end users. The solution is to test AI products on a set of real-world examples, aka “evals”.
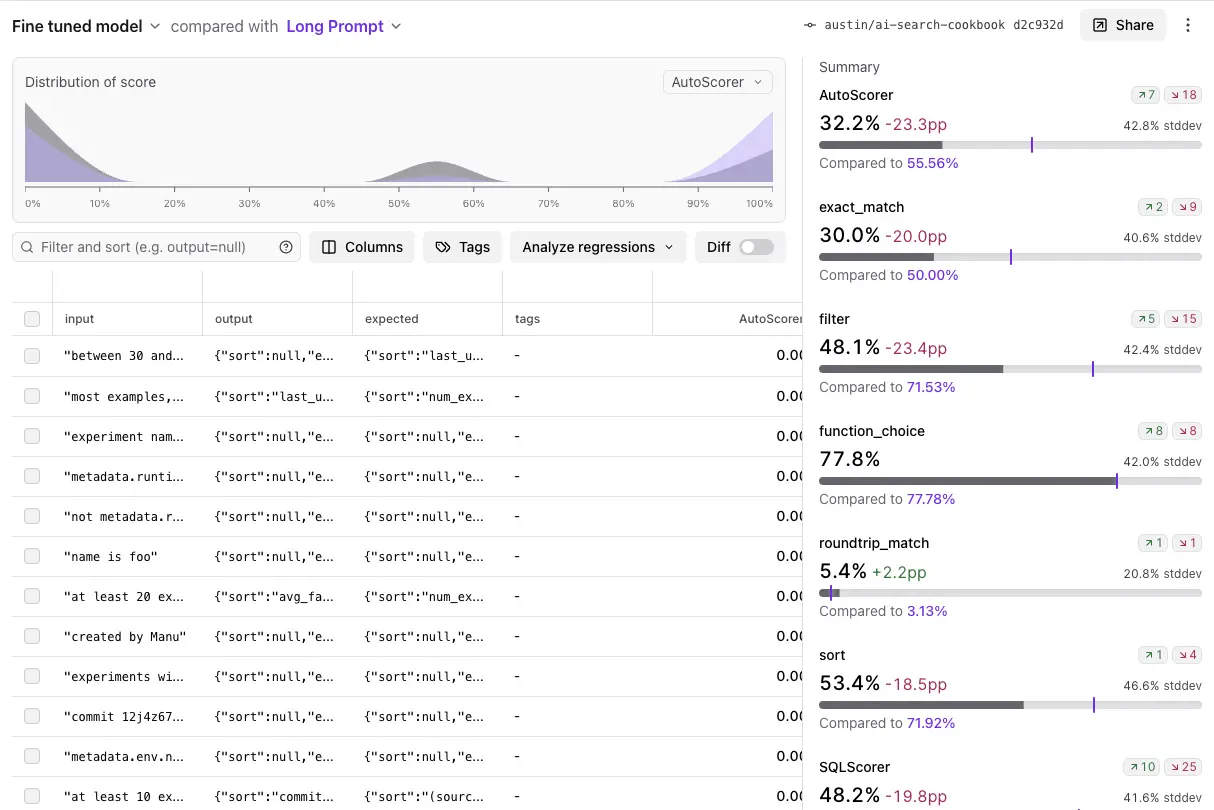
Once you establish an initial set of evals, however, a few problems typically emerge:
- It’s hard to find great eval data
- It’s hard to identify interesting cases / failures in production
- It’s hard to tie user feedback to your evals
The solution to these problems is to connect your real-world log data to your evals, so that as you encounter new and interesting cases in the wild, you can eval them, improve, and avoid regressing in the future. In this post, we’ll work through how to set this up in the ideal way.
Specifically, we’ll cover:
- How to structure your evals and when to run them
- How to flow production logs into your eval data
- How Braintrust makes this seamless
Structuring your evals
Well-implemented evals serve as the foundation of the AI engineering dev loop. If you can run them "offline" from your production application, evals free you to experiment with changes to code, prompts, data, etc. without affecting your users.
Fundamentally, an eval is a function of some (a) data, (b) prompts/code (we’ll call this a task), and (c) scoring functions. Updating the (b) task impacts product behavior, while updating the (a) data or (c) scorers improves the fidelity of the evaluation. Consequently, each time any of these change, you should run a new eval and assess how your performance has changed.
Braintrust’s Eval function makes this workflow very clear, by literally having 3 inputs:
Eval("project name", {
data: <your data>,
task: <your task>,
scores: [Factuality, Levenshtein, ...],
})
In the next section of this post, we’re going to focus in on the “data” part. And in particular, how to build and continually improve your datasets, by capturing real-world data the right way.
Capturing and utilizing logs
The key to evaluating with good data is to use real-world examples. When we’re playing with AI products, we often discover good test cases while interacting with them. For example, someone may struggle to get your chatbot to produce a markdown table. When this happens, it’s the perfect moment to capture the context into a dataset you evaluate on.
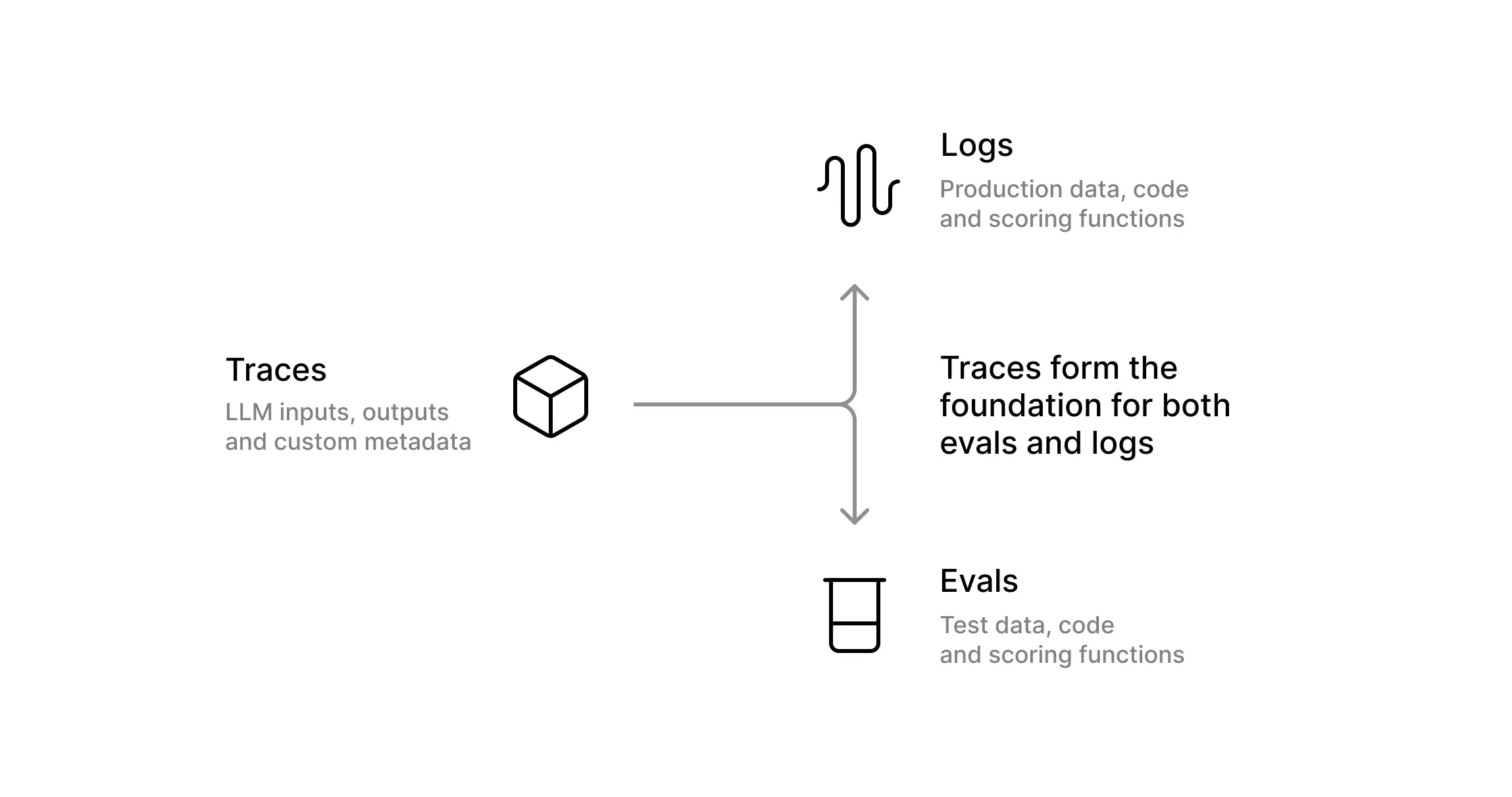
Because logs and evals function similarly, the data from logs can quickly be used to power your evals.
Initial steps
We highly recommend tracing and logging your projects from inception. In the early days of developing a new product or feature, each time someone encounters a bug, you can immediately find the trace corresponding to their interaction in the UI. You can also scan through most or all traces to look for patterns. This is a benefit of small scale 🙂.
Braintrust makes this seamless. To log user interactions, you instrument your application’s code to trace relevant bits of context. Traces appear on the logs page, where you can view them in detail.
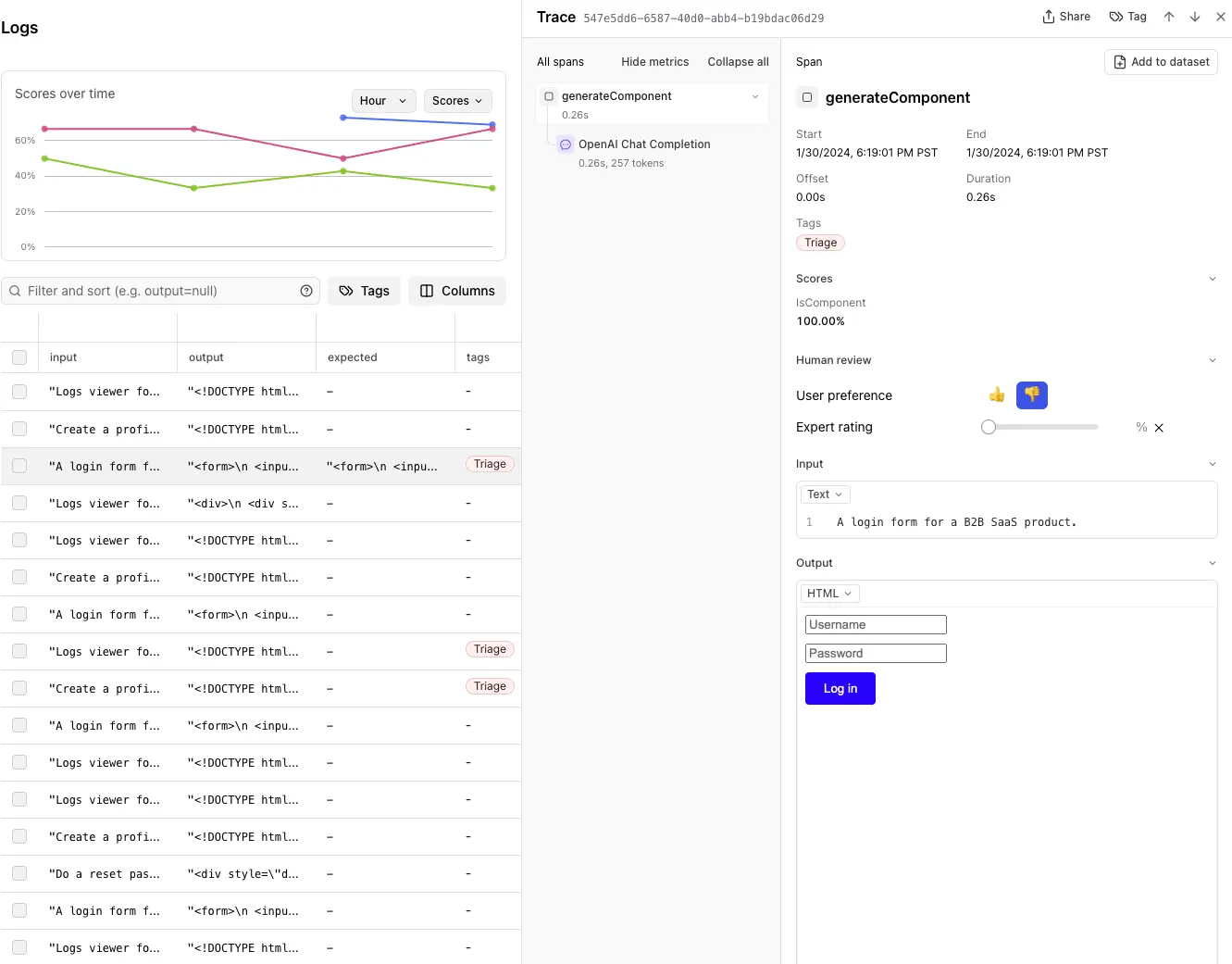
As you find interesting examples in your logs, you can quickly add them to a dataset. You can also use tags to organize different kinds of issues, e.g. toxic-input, but you can also place different categories of logs into separate datasets.
Once you set up a dataset, you can run evals on it by referencing it as the data parameter in the Eval function:
Eval("your project", {
data: init_dataset("your project", "your dataset"),
...
})
As you add new cases to your dataset, your Eval will automatically test them. You can also pin an Eval to a particular version of a dataset, and then explicitly change the version when you’re ready to.
Scaling
As you scale, it becomes critical to filter the logs to only consider the interesting ones. There are three ways to accomplish this:
- Use filters, e.g. on
metadataortags, to help you track down interesting cases. For example, you might know that your evals are missing a certain type of request, filter down to them, scan a few, and add 1-2 to your eval dataset. - Track user feedback, and review rated examples. For example, you may routinely capture 👍🏽 cases as positive cases not to regress, or carefully review recent 👎🏽 cases, and add them to a dataset for further improvement.
- Run online scores, ideally the same scores you do offline evals on, and find low scoring examples. This is a fantastic and very direct way to uncover test cases that you know need improvement by your own metrics.
Putting this to practice
Implementing a good eval feedback loop is incredibly rewarding, but can get unwieldy, even at relatively small scale. Many teams we meet start with json data in their git repo or source code. But they quickly find that it’s a lot of manual effort to keep these files up-to-date with real-world examples, collaborate on them, and visualize the data.
Braintrust is specifically built and designed for this purpose:
- You can instrument your code once and reuse it across both logging and evaluation. For example, if you implement a score while evaluating (e.g. ensuring the length of an output is at most 2 paragraphs), you can automatically compute the score in production, discover examples where it’s low, and add them to a dataset.
- The shared code across logging and evals also naturally unifies the UI. This is one of the most powerful ideas in Braintrust — you can use exactly the same code and UI to explore your logs and your evals. The trace is an incredibly powerful data structure that contains information about every LLM call plus additional data you log. You can even reproduce the LLM calls your users saw, tweak the prompts, and test them directly in the UI.
- All of your datasets, logs, evals, and user data can be stored in your cloud environment. We know how sensitive and valuable your AI data is, so we’ve supported self-hosting from day one.
If you think Braintrust can help, then feel free to sign up or get in touch. We’re also hiring!