Contributed by Ankur Goyal on 2024-02-02
This tutorial walks through how to automatically generate release notes for a repository using
the Github API and an LLM. Automatically generated release notes are tough to evaluate,
and you often don’t have pre-existing benchmark data to evaluate them on.
To work around this, we’ll use hill climbing to iterate on our prompt, comparing new results to previous experiments to see if we’re making progress.
Installing dependencies
To see a list of dependencies, you can view the accompanying package.json file. Feel free to copy/paste snippets of this code to run in your environment, or use tslab to run the tutorial in a Jupyter notebook.Downloading the data
We’ll start by downloading some commit data from Github using theoctokit SDK. We’ll use the Braintrust SDK from November 2023 through January 2024.
Generating release notes
Awesome! It looks like we have 9 solid weeks of data to work with. Let’s take a look at the first week of data.Building the prompt
Next, we’ll try to generate release notes usinggpt-3.5-turbo and a relatively simple prompt.
We’ll start by initializing an OpenAI client and wrapping it with some Braintrust instrumentation. wrapOpenAI
is initially a no-op, but later on when we use Braintrust, it will help us capture helpful debugging information about the model’s performance.
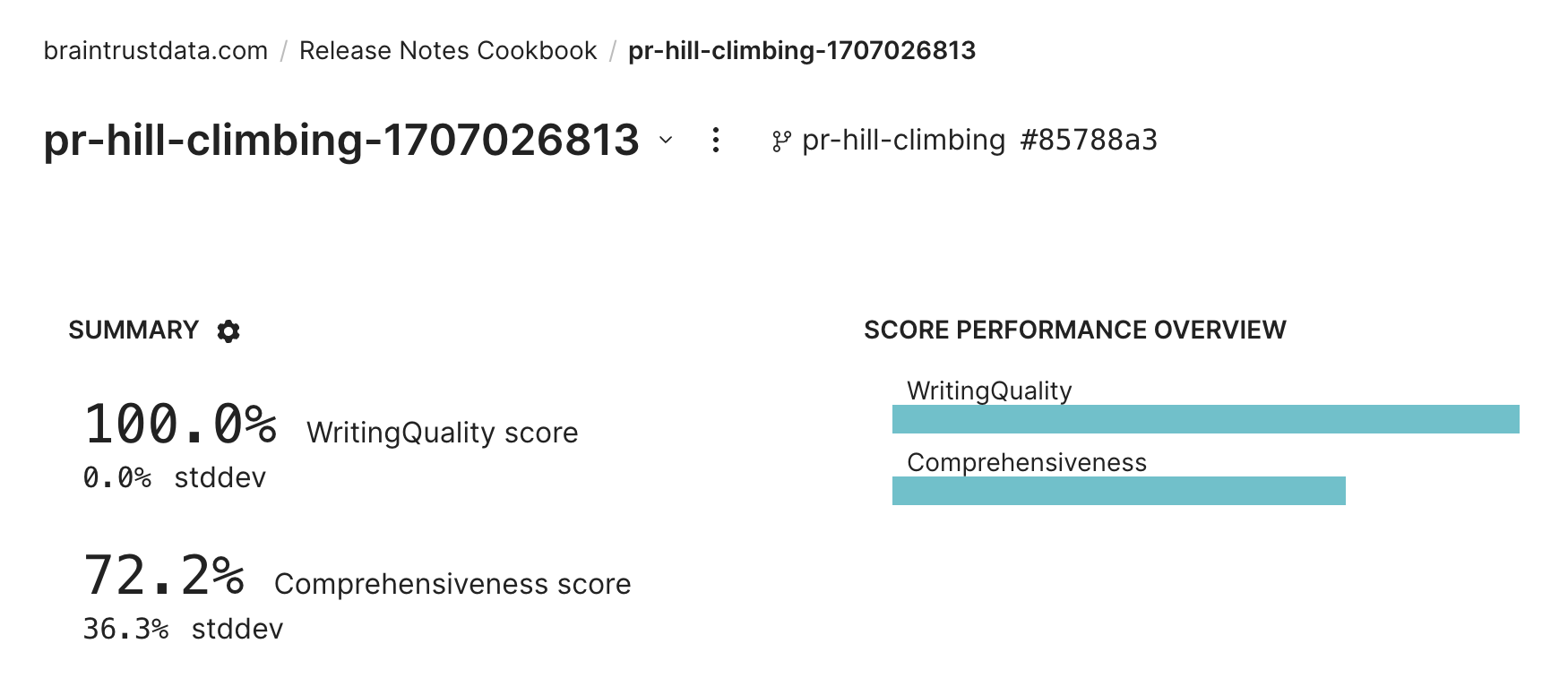
Evaluating the initial prompt
Interesting, at a glance, it looks like the model is doing a decent job, but it’s missing some key details like the version updates. Before we go any further, let’s benchmark its performance by writing an eval.Building a scorer
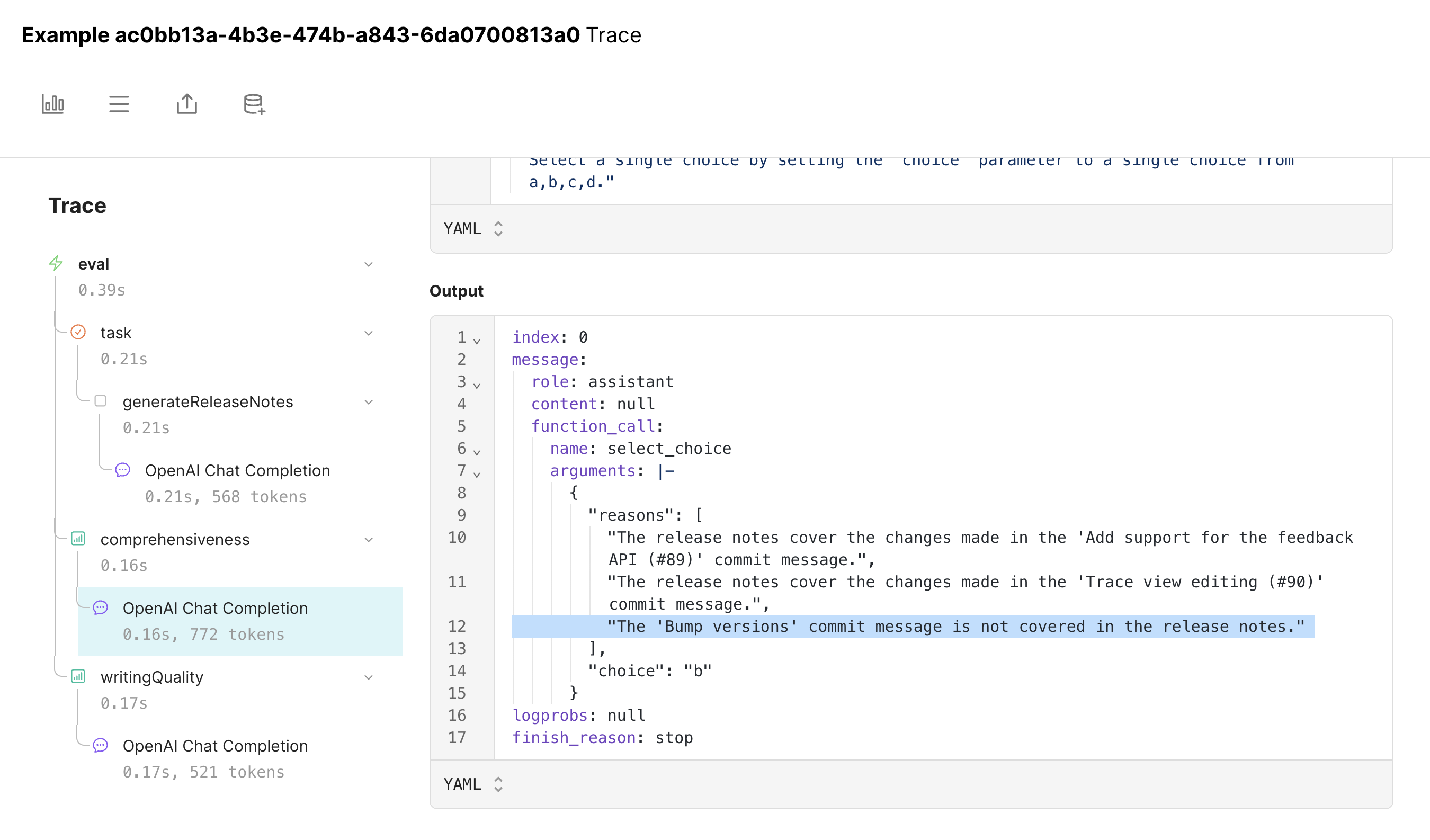
Let’s start by implementing a scorer that can assess how well the new release notes capture the list of commits. To make the scoring function job’s easy, we’ll do a few tricks:- Use gpt-4 instead of gpt-3.5-turbo
- Only present it the commit summaries, without the SHAs or author info, to reduce noise.
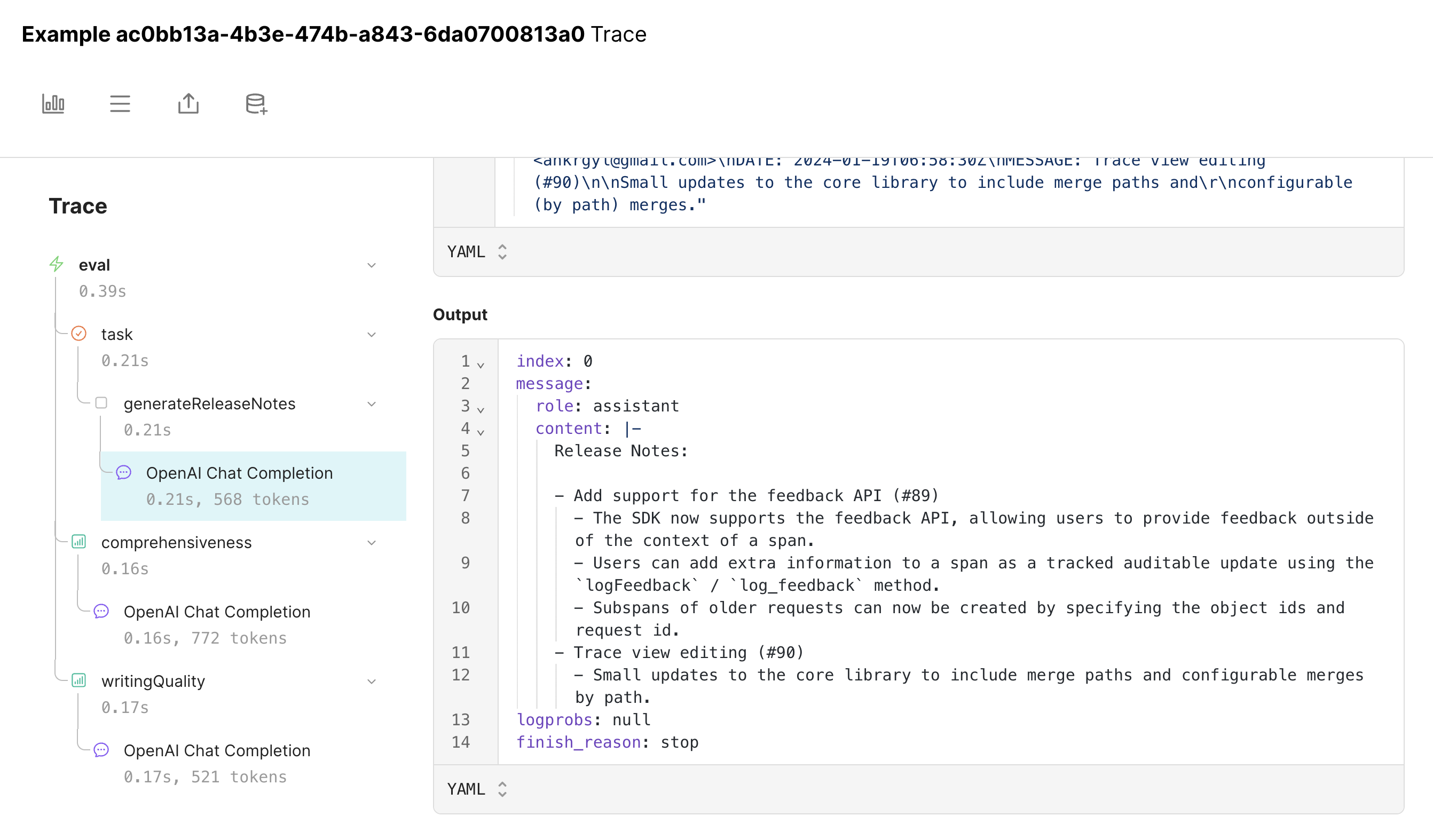
Improving the prompt
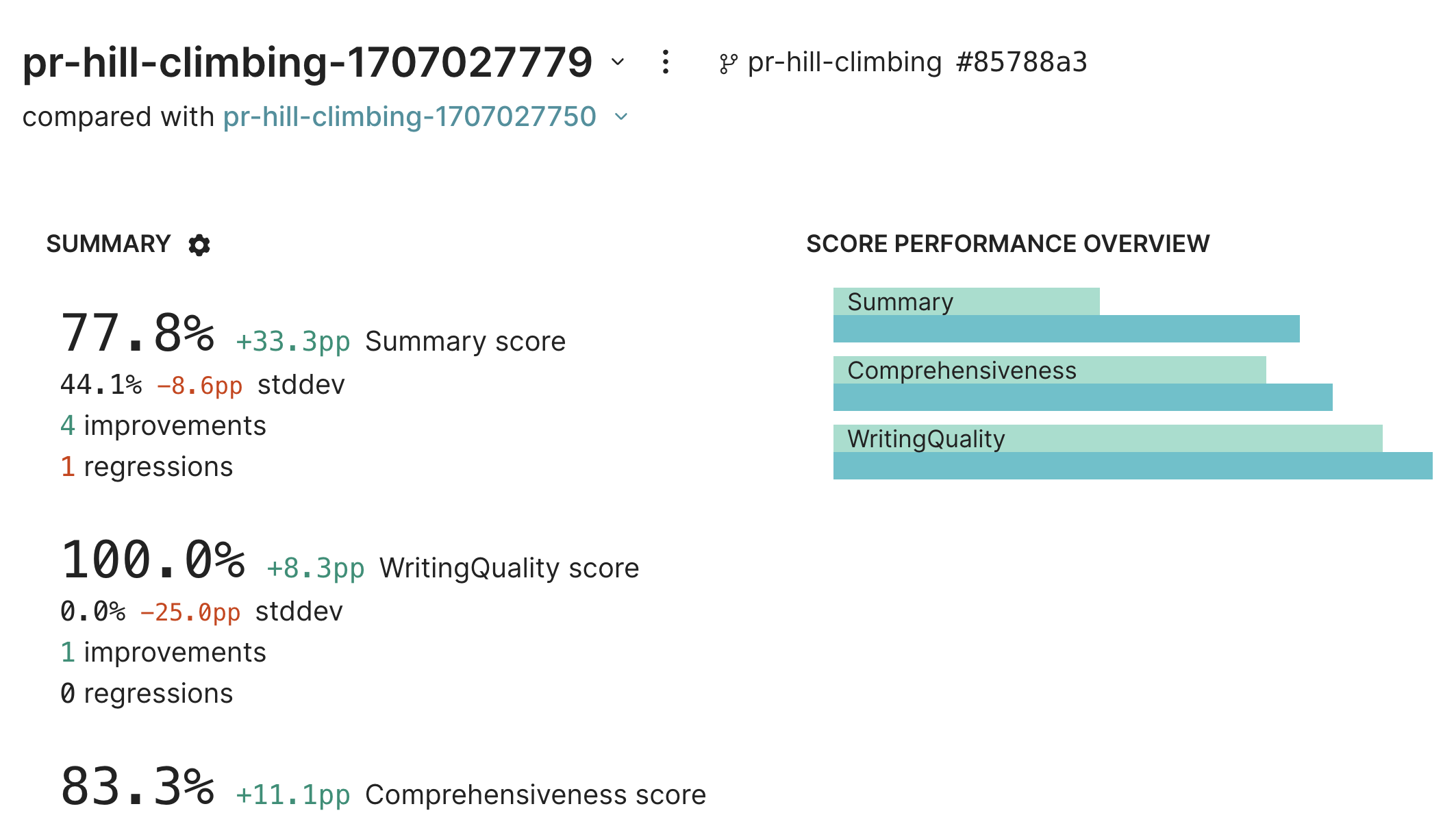
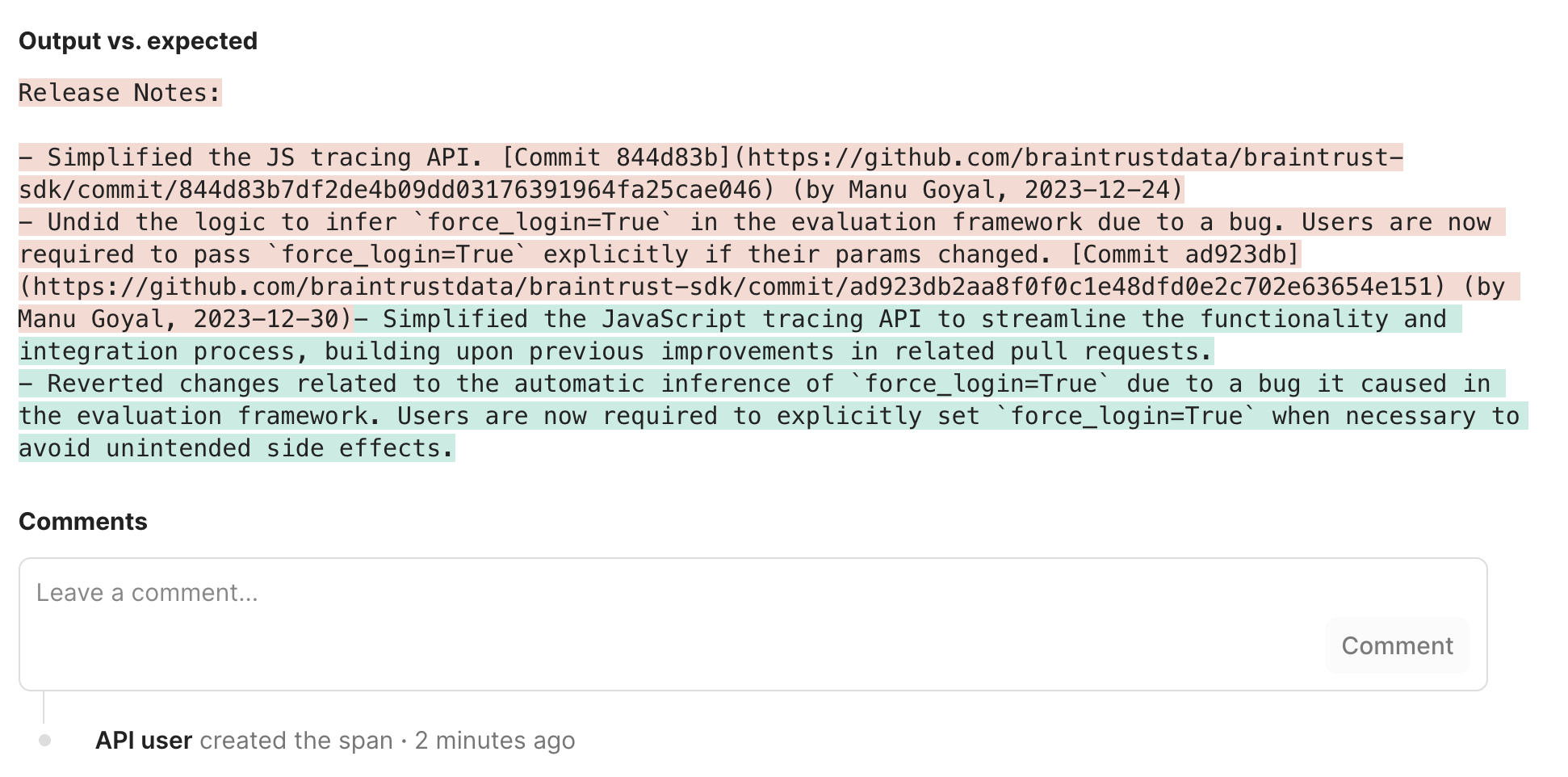
Let’s see if we can improve the model’s performance by tweaking the prompt. Perhaps we were too eager about excluding irrelevant details in the original prompt. Let’s tweak the wording to make sure it’s comprehensive.Hill climbing
We’ll use hill climbing to automatically use data from the previous experiment to compare to this one. Hill climbing is inspired by, but not exactly the same as, the term used in numerical optimization. In the context of Braintrust, hill climbing is a way to iteratively improve a model’s performance by comparing new experiments to previous ones. This is especially useful when you don’t have a pre-existing benchmark to evaluate against. Both theComprehensiveness and WritingQuality scores evaluate the output against the input, without considering a comparison point. To take advantage of hill climbing, we’ll add another scorer, Summary, which will compare the output against the data from the previous experiment. To learn more about the Summary scorer, check out its prompt.
To enable hill climbing, we just need to use BaseExperiment() as the data argument to Eval(). The name argument is optional, but since we know the exact experiment to compare to, we’ll specify it. If you don’t specify a name, Braintrust will automatically use the most recent ancestor on your main branch or the last experiment by timestamp as the comparison point.
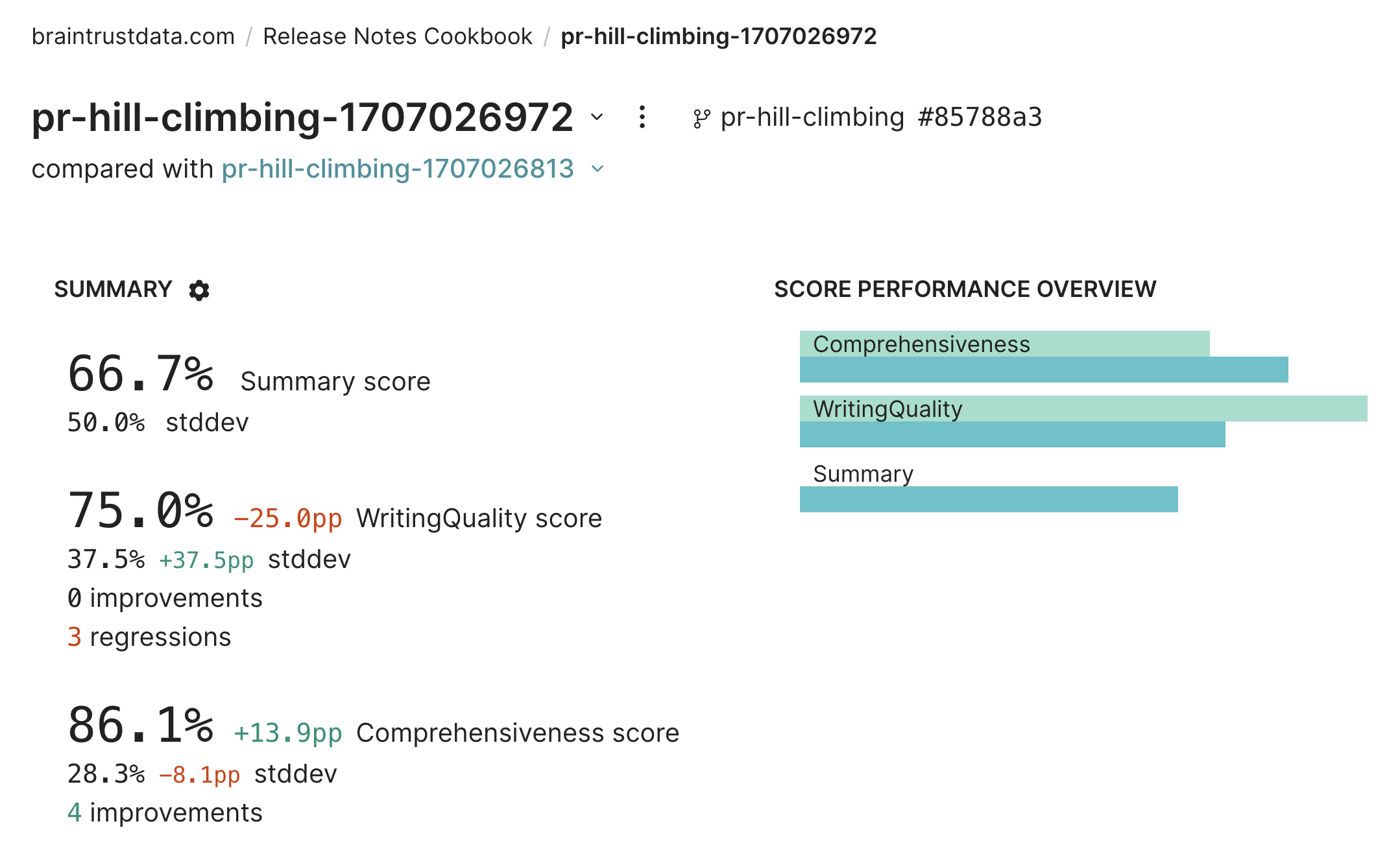
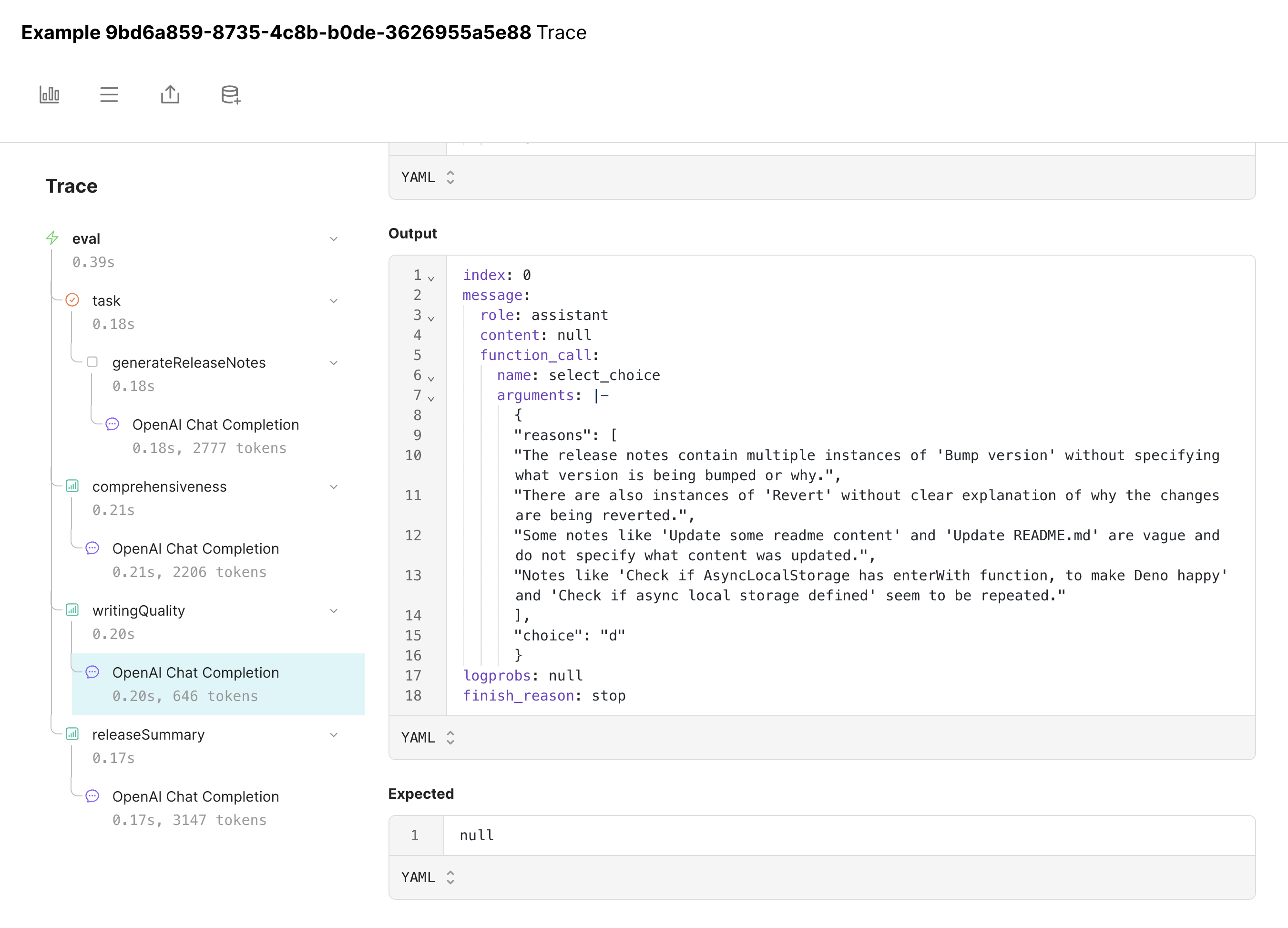
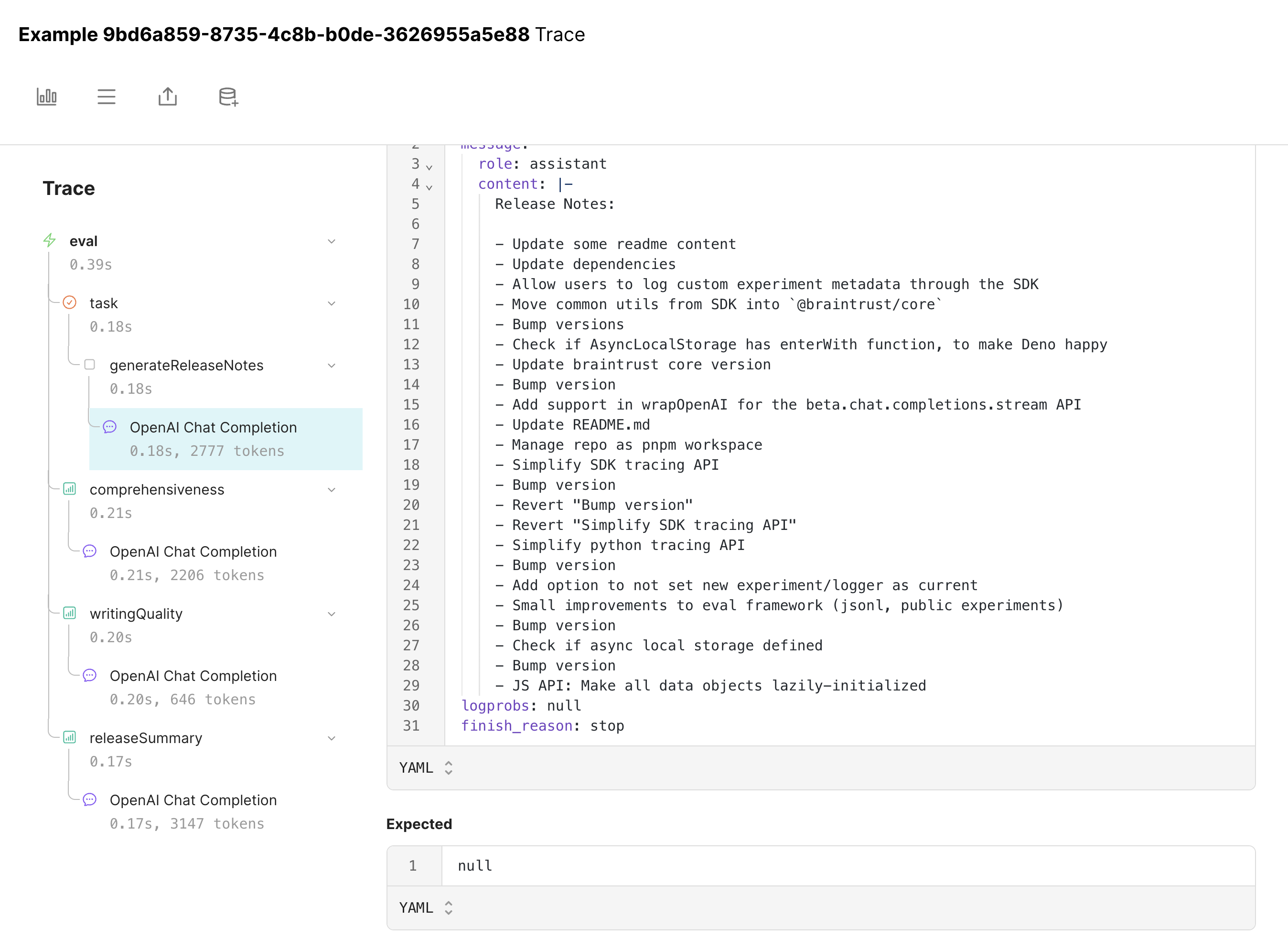
Iterating further on the prompt
Let’s try to address this explicitly by tweaking the prompt. We’ll continue to hill climb.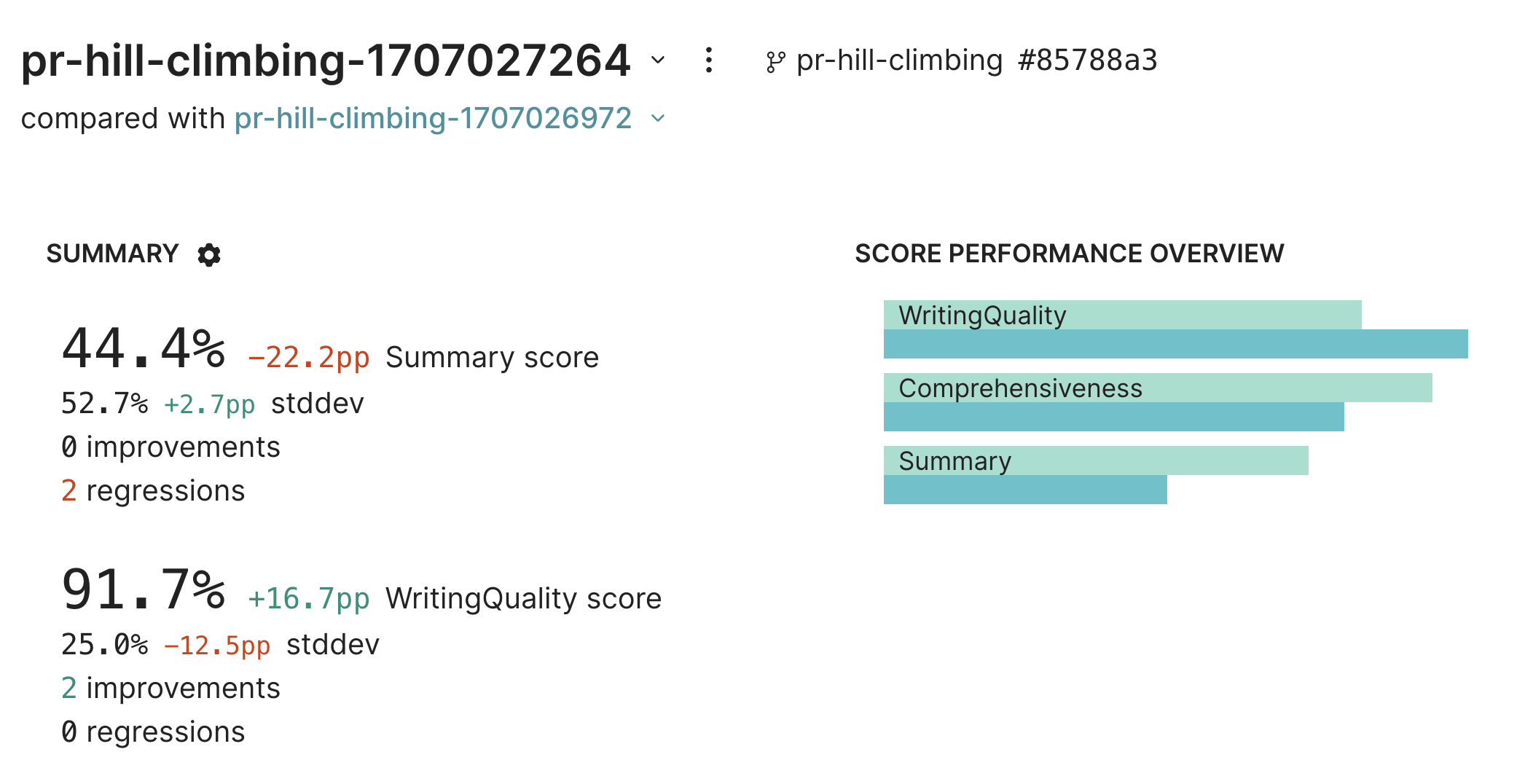
Upgrading the model
Let’s try upgrading the model togpt-4-1106-turbo and see if that helps. Perhaps we’re hitting the limits of gpt-3.5-turbo.